Achieving Human-Scale Context: Two-Round Re-ranking for Complete RAG Retrieval
Although Large Language Models (LLMs) continue to advance rapidly, they are intrinsically limited by their training data and cannot spontaneously acquire the latest or proprietary domain knowledge. Retrieval-Augmented Generation (RAG) addresses this by consulting relevant information from a knowledge base before generating an answer, effectively transitioning the LLM from a self-contained model to one that actively references external sources.
However, the quality of the output is heavily dependent on the quality of the input. If the retrieved documents are incomplete or inaccurate, even a powerful LLM cannot deliver a high-quality response. Therefore, retrieval is the key component of RAG, and its success is measured by the system’s ability to completely and accurately find the most relevant content for the user’s query.
I. Document Chunking: The Cost of Semantic Fragmentation
Nearly all RAG systems adhere to a standard pipeline:
Document Parsing → Text Chunking → Vectorization → Preliminary Retrieval → Fine-grained Re-ranking → Large Language Model Generation
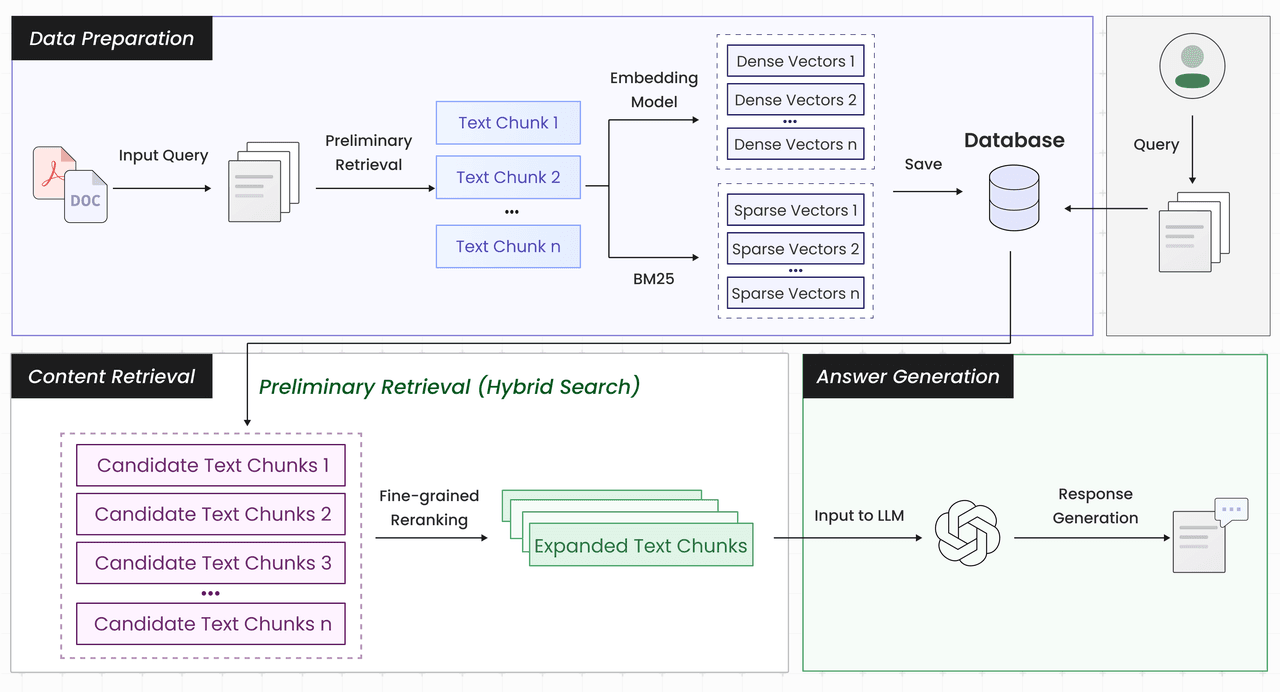
Text chunking is a necessary step because retrieval models operate under strict input length limitations. While using smaller chunks can improve semantic matching precision, chunking is the primary factor degrading RAG retrieval quality.
This mechanical fragmentation of coherent long documents often leads to incomplete retrieval due to semantic loss, ambiguity, or the destruction of panoramic structural information.
A clear illustration is provided by the Laws of the Game 2024_25 example. Under a fixed-length chunking strategy, content about "Reviewable match-changing decisions" may be split into two chunks.
<文本块 1> page 144
2. Reviewable match-changing decisions/incidents
The referee may receive assistance from the VAR only in relation to four categories of match-changing decisions/incidents. In all these situations, the VAR is only used after the referee has made a (first/original) decision (including allowing play to continue), or if a serious incident is missed/not seen by the match officials.
The referee’s original decision will not be changed unless there was a ‘clear and obvious error’ (this includes any decision made by the referee based on information from another match official e.g. offside).
The categories of decision/incident which may be reviewed in the event of a potential ‘clear and obvious error’ or ‘serious missed incident’ are:
a. Goal/no goal
• attacking team offence in the build-up to or scoring of the goal (handball, foul, offside etc.)
• ball out of play prior to the goal
• goal/no goal decisions
• offence by goalkeeper and/or kicker at the taking of a penalty kick or encroachment by an attacker or defender who becomes directly involved in play if the penalty kick rebounds from the goalpost, crossbar or goalkeeper
<文本块 2> page 155
b. Penalty kick/no penalty kick
• attacking team offence in the build-up to the penalty incident (handball, foul, offside etc.)
• ball out of play prior to the incident
• location of offence (inside or outside the penalty area)
• penalty kick incorrectly awarded
• penalty kick offence not penalised
c. Direct red cards (not second yellow card/caution)
• DOGSO (especially position of offence and positions of other players)
• serious foul play (or reckless challenge)
• violent conduct, biting or spitting at another person
• using offensive, insulting or abusive action(s)
d. Mistaken identity (red or yellow card)
If the referee penalises an offence and then gives the wrong player from the offending (penalised) team a yellow or red card, the identity of the offender can be reviewed; the actual offence itself cannot be reviewed unless it relates to a goal, penalty incident or direct red card.
When a user asks, "In which situations can the referee use VAR to review a potential clear and obvious error?":
- Text Chunk 1, which provides the definition, is successfully retrieved by the system because it includes the keyword "potential clear and obvious error."
- Text Chunk 2, which lists the subsequent items, is likely to be missed by the retrieval system due to the absence of a proper title and context, leading to a lower semantic matching score.
As a result, the LLM ultimately answers only the first four items of the regulation, omitting the latter three. The semantic fragmentation caused by chunking is the root cause of RAG producing incomplete answers.
The resulting LLM answer is incomplete, confirming that semantic fragmentation caused by chunking is the root cause of "incomplete answers" in RAG.
II. The Impossibility of Optimal Static Chunking
Fragmentation poses significant challenges, raising the question of whether optimizing chunking rules can solve this issue. However, achieving this is extremely complex due to the diversity of document formats and varying content structures.
For example, in the document UMass Amherst Writing Program Student Writing Anthology, elements such as titles, authors, and comments use various non-uniform formats, making it extremely difficult to adopt a single, universal chunking rule.

Moreover, the effectiveness of chunking depends on the specific query, which remains unknown during the chunking phase. As a result, determining the optimal chunking approach in advance is impractical.
Ambiguity in Complex Documents
In complex documents, like the Competitive Programmer’s Handbook example, answering a simple question like "How significant are the efficiency gaps between the algorithms introduced in the Data Structures chapter?" requires linking context across these disparate pages:

- Page 33 states: "Efficiency comparison. It is interesting to study how efficient algorithms are in practice. The following table shows the running times of the above algorithms..."
- Page 55 states: "Efficiency comparison. The following table shows how efficient the above algorithms"
Just by looking at these two segments, it is impossible to determine which specific "algorithm" is being referenced. We must rely on Page 27 (Chapter 2 Time complexity) and Page 35 (Chapter 4 Data Structure) to confirm that the "algorithm" on Page 33 refers to "Time complexity" in Chapter 2 and the "algorithm" on Page 55 refers to "Data Structure" in Chapter 4.
To correctly identify the entities involved, it's necessary to place Page 27-33 (7 pages) into one text chunk and Page 45-55 (11 pages) into another. However, such large blocks often exceed retrieval model limits and simultaneously reduce precision for other detail-oriented questions. Therefore, a "perfect" static chunking solution that adapts to all future queries does not exist, and the destruction of semantic coherence remains unavoidable.
III. Context Re-ranking: Holistic Evaluation and Its Limitations
If chunking cannot be fixed, the solution may be implemented during the retrieval phase.
Major retrieval solutions rely on a "piece-by-piece evaluation", which accesses the relevance of individual chunks in isolation, but overlooks the context-loss issues caused by chunking.
This study addresses the "Context Re-ranking" mode by employing a "holistic evaluation". This process concatenates the candidate text chunks (after de-duplication and ordering by their original sequence) into a single continuous text and feeds it into the re-ranking model in one step.
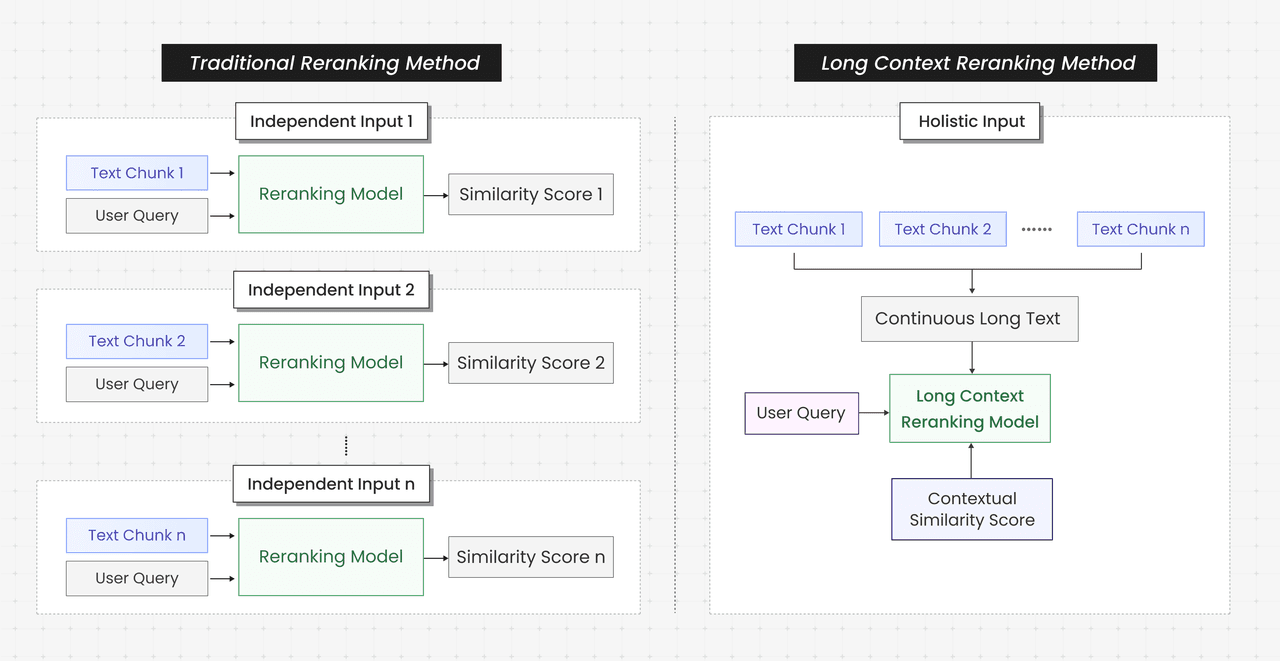
The mechanism allows the re-ranking model to perceive semantic correlation between segments, leading to a more accurate assessment of relevance.

Back to the Laws of the Game example, when Chunks 1 and 2 are recalled, the holistic model processes them together, recognizes Chunk 2 as a continuation, and returns the complete regulation corresponding to "Reviewable match-changing decisions/incidents".
Limitations
Context Re-ranking is not a universal solution. If the preliminary retrieval results exceed the context window (e.g., 60k tokens) in a very long document, an initial filtering step is still required, risking critical information omission.
The approach's effectiveness ultimately depends on whether preliminary retrieval successfully "fetched" the critical chunks. If key information is lost in the initial vector search due to low semantic similarity, the powerful re-ranking model cannot compensate. For instance, UMass Amherst Writing Program Student Writing Anthology essay was split into 4 chunks.
For the question "What is the full text of TIFFANY KHANG’s essay?", the preliminary retrieval's 60k content only included Chunks 1 and 2, and traditional re-ranking only recalled Chunk 1. Even with the introduction of context re-ranking, Chunks 1 and 2 were successfully recalled in the initial step, but Chunks 3 and 4 were filtered out during the preliminary retrieval phase due to low semantic similarity.
IV. Context Extension: Achieving Human-Level Context Awareness
Before RAG, humans acquired knowledge by reading, judging segment relevance, and "flipping back and forth" to complete the context. Since LLMs cannot actively turn pages or scan the surrounding context, they must rely entirely on the given segments. This means RAG requires significantly higher completeness than traditional search engines, the retrieval mechanism itself must ensure information sufficiency.
Initial Attempts and Their Failure: Context Extension + Re-ranking
An early strategy, Context Extension + Single Re-ranking, used preliminary vector similarity scores to define the extension range. Higher scores corresponded to a broader extension range for the surrounding text.

This provided only limited improvement because many critical missing segments in the initial retrieval were still not supplemented.
The retrieval workflow of "UMass Amherst Writing Program Student Writing Anthology" can be broken down as:
Preliminary retrieval recalled only Chunks 1 and 2.
Performing context extension on Chunks 1 and 2.
Due to the low scores of Chunks 1 and 2, only Chunk 3 was incorporated into the candidate set, while Chunk 4 was not.
Chunks 1, 2, and 3 were then input to the re-ranking model, Chunk 4 was missed in the generated answer.
This highlights the necessity of accurately identifying key chunks before extending the context.
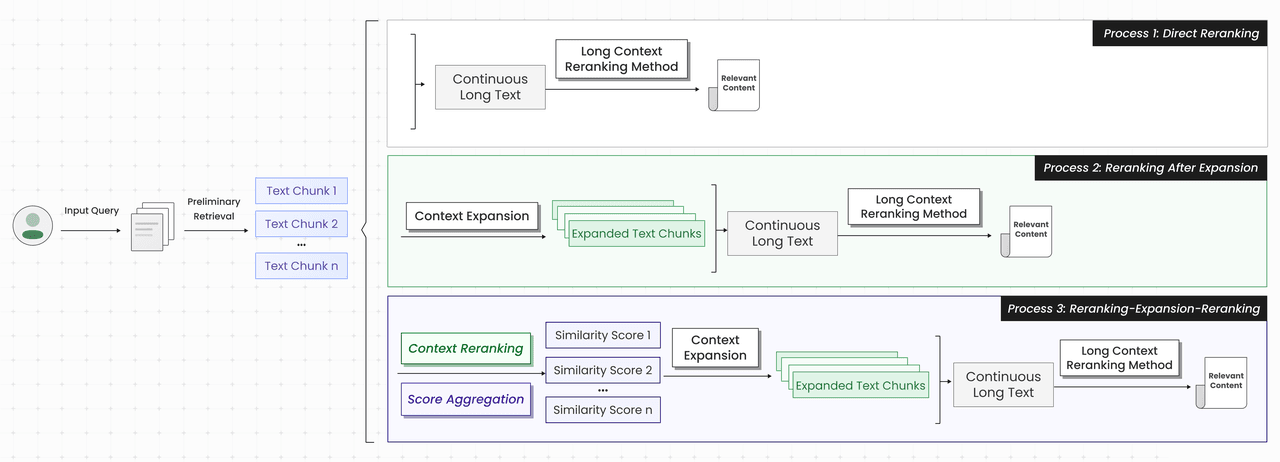
The Solution: Context Extension + Two-Round Re-ranking
The proposed solution "Context Extension + Two-Round Re-ranking" introduces two distinct re-ranking phases:
- First Round Re-ranking: A context re-ranking model precisely scores the results from preliminary retrieval.
- Context Extension: Based on these re-ranking scores, adjacent unrecalled text segments (both preceding and succeeding those with high scores) are added to the candidate set. Higher scores result in a broader expansion range.
- Second Round Re-ranking: The fully extended candidate set undergoes a final re-ranking to select the optimal content for the LLM.

This process grants the RAG system a human-like "scanning" ability: first locating the most relevant paragraphs, then extending their context, and finally judging relevance based on the more complete environment.
Returning to the UMass Amherst Writing Program Student Writing Anthology, the optimized workflow would be:
Preliminary retrieval only recalled Chunks 1 and 2.
After the first re-ranking, they received relatively high scores
Context extension then incorporated the adjacent Chunks 3 and 4
The second re-ranking identified all content.
Chunks 1-4 were input to the LLM, generating an accurate and complete answer
This demonstrates that "Context Extension + Two-Stage Re-ranking" provides the RAG system with a stronger ability to perceive semantic coherence.
V. Empirical Results: Validating the Two-Round Approach
To validate the strategy, an evaluation set of 855 questions was constructed across 50 long documents, with each question referencing an average of 11.3 relevant paragraphs.
The experiment compared 6 retrieval solutions using the BGE-M3 vector model for preliminary retrieval:
no_rerank,
bge_rerank (piece-by-piece),
jina_rerank (holistic),
context_rerank (Process 1),
extend_rerank (Process 2),
rerank_extend_rerank (Process 3).
Results were measured by calculating the average recall rate against human-annotated results, truncating the final context to 1K, 5K, and 10K tokens.
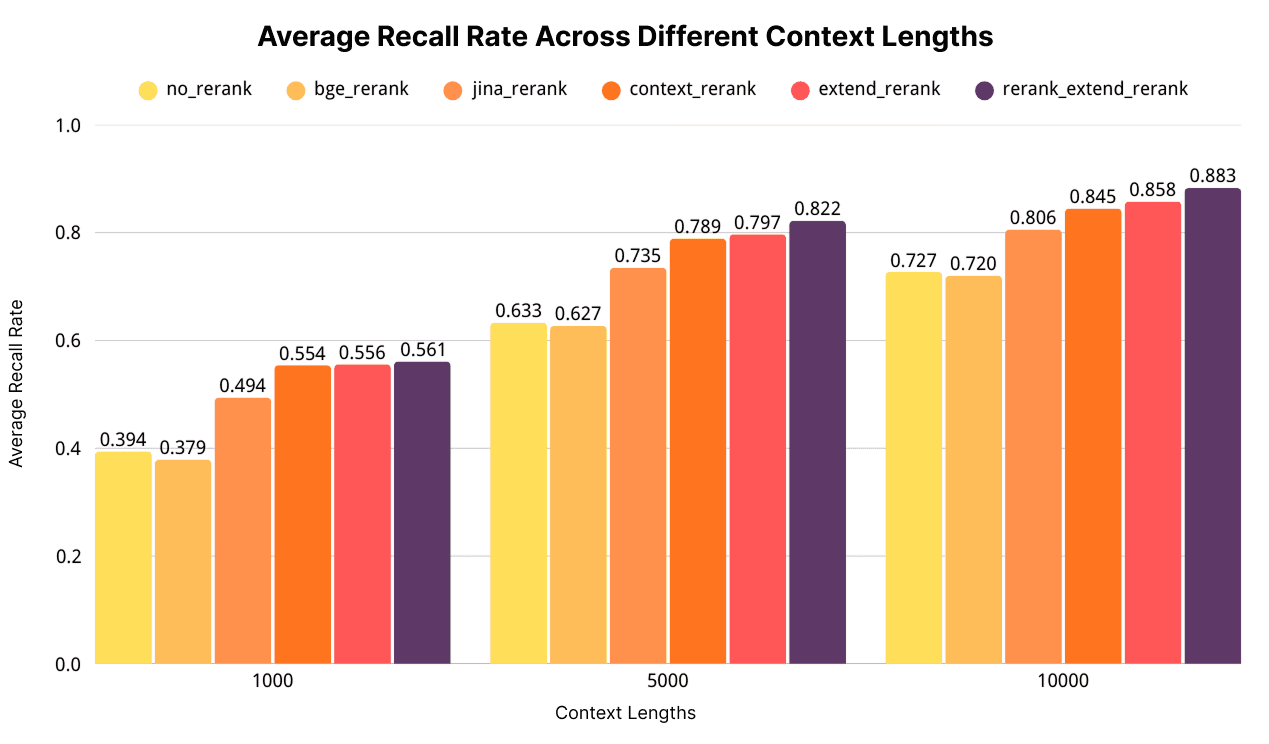
Key Findings
- For long-context queries, re-ranking models using the "holistic evaluation" approach significantly outperformed those using "piece-by-piece evaluation".
- The "Context Extension + Two-Round Re-ranking" strategy (rerank_extend_rerank) achieved the best performance across all recall lengths, substantially enhancing retrieval completeness.
VI. Conclusion: Overcoming the Fragmentation Bottleneck
Document chunking is an unavoidable engineering compromise in RAG systems, but the semantic fragmentation it introduces is the greatest threat to retrieval completeness.
The "Context Extension and Two-Round Re-ranking" strategy fundamentally shifts the retrieval logic, enabling the RAG system to imitate human reading habits by relying on clues to scan the surrounding context, rather than viewing isolated segments. This method effectively bridges information gaps at extremely low cost without changing underlying chunking rules. For enterprise RAG applications demanding high precision and completeness, this is potentially the most effective path to break through the "quoting out of context" bottleneck.
This "Context Extension and Two-Round Re-ranking" technology is available in ChatDOC Studio.
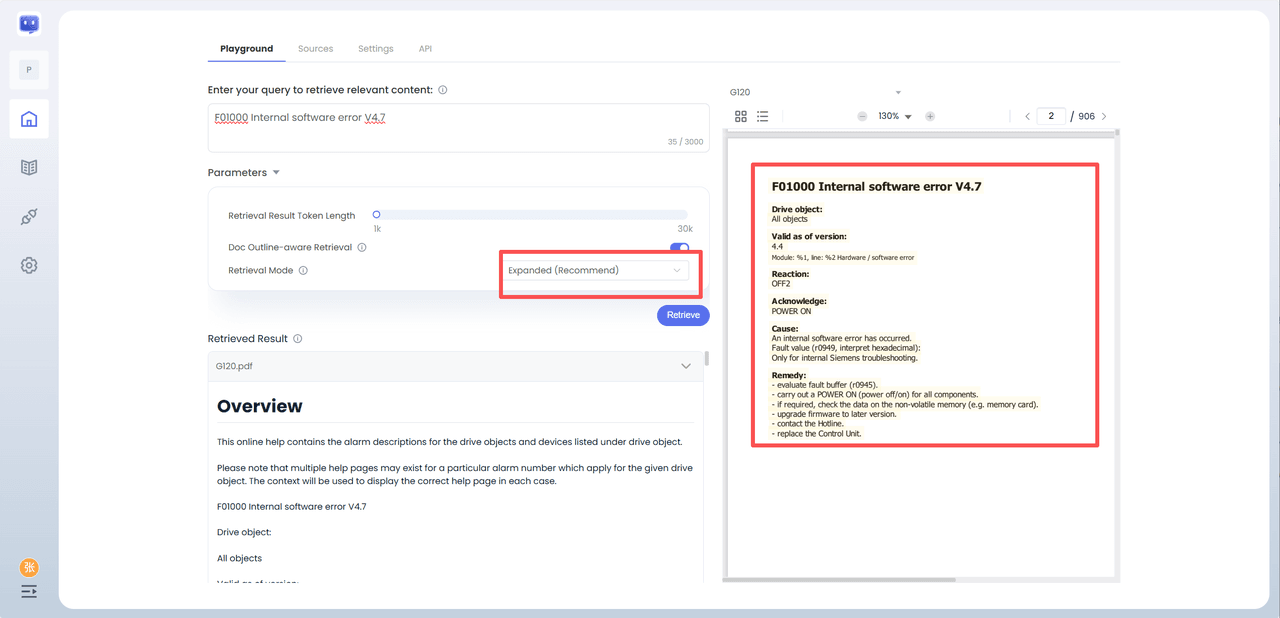
For instance, testing the G120 document showed that the 'Expanded (Recommended)' mode completely recalled the full essay text within the 6k token limit, a significant advantage over 'Basic' or 'Contextual' modes.
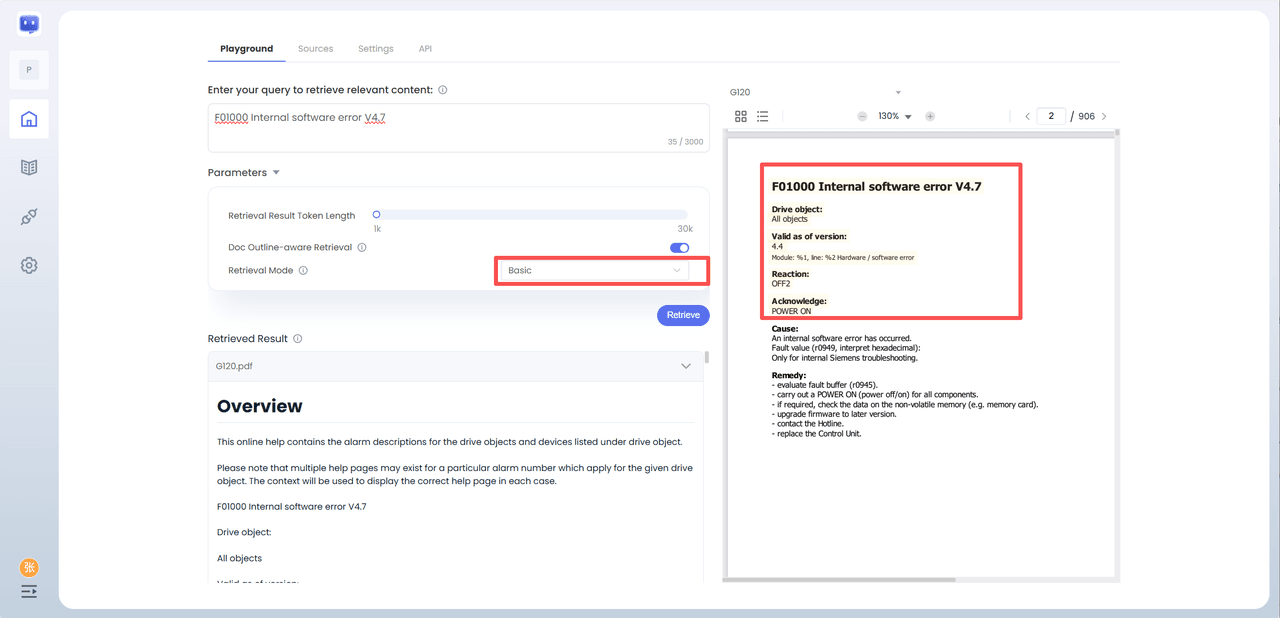
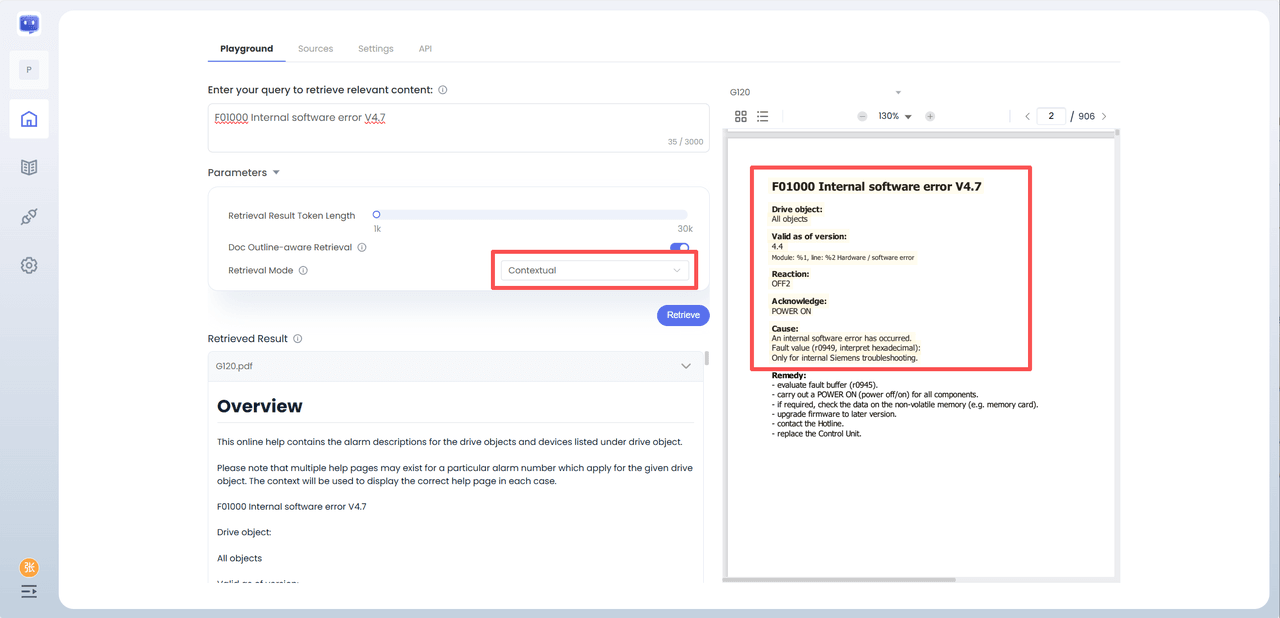
"Basic" mode or "Contextual (Context Extension + Context Re-ranking)" mode: only able to retrieve the text chunk containing the author's name at the 6k token length, thus missing critical information in the retrieval step.
"Expanded (Recommended)" mode: employs "Context Extension + Two-Stage Re-ranking," the full text of Shi Yuanda's essay was completely recalled within the same token length. - "Expanded (Recommended)" mode: employs "Context Extension + Two-Stage Re-ranking," the full text of Shi Yuanda's essay was completely recalled within the same token length.
This demonstrates the significant advantage of "Context Extension + Two-Stage Re-ranking" in improving retrieval completeness in practical applications.
Related Articles
ChatDOC Studio Quick Start Guide
ChatDOC Studio allows rapid creation of AI applications (Chat, Context Retrieval, PDF Parser) in four steps: Sources, Configure, Test, and Launch. The Chat App acts as a file-grounded customer service assistant, offering multiple integration styles (Floating, iFrame, URL, API). The Context Retrieval App provides highly accurate, context-aware information retrieval. The PDF Parser converts documents into structured, LLM-ready data.
Turn Business Documents into 24/7 AI Expert with ChatDOC Studio
ChatDOC Studio transforms static business documents into intelligent, interactive chatbots. This no-code platform allows you to upload files or websites to create 24/7 AI assistants that streamline employee onboarding and automate customer support with accurate, source-traced answers. With full brand customization and seamless website integration, ChatDOC Studio makes internal and external knowledge instantly accessible. Start with the free plan to supercharge your business efficiency and accelerate growth with advanced document-based AI.